
Las redes neuronales profundas son potentes. Sin embargo, tienden a olvidar la información aprendida previamente mientras aprenden información nueva. Esto se llama olvido catastrófico. Este fenómeno se ha estudiado ampliamente en el contexto del aprendizaje continuo, en el que un modelo de aprendizaje automático aprende continuamente de un entorno en constante evolución. Sin embargo, el olvido catastrófico parece aparecer en muchos otros entornos, por ejemplo en el aprendizaje distribuido. En este artículo, estudiamos el aprendizaje federado dividido (Split Federated Learning, SFL), un nuevo paradigma de aprendizaje distribuido que permite a los dispositivos formar un modelo de forma colaborativa y descargar parte de la formación en un servidor computacionalmente potente. La heterogeneidad de datos entre dispositivos puede empeorar el olvido. Para hacer frente a este problema, diseñamos Hydra, un nuevo método inspirado en las redes neuronales multicabezal que mantiene la precisión de los modelos reduciendo el efecto del olvido.
¿Qué es el olvido catastrófico?
En los escenarios reales de aprendizaje automático, un modelo necesita aprender de un flujo continuo de entradas (datos). Sin embargo, el conocimiento de la Tarea 1, por ejemplo reconocer vehículos o aviones en imágenes (para modelos de reconocimiento de imágenes), puede verse interrumpido/perdido al adquirir conocimiento relacionado con la siguiente tarea, la Tarea 2, por ejemplo reconocer gatos o perros. Este fenómeno se denomina «olvido catastrófico». De hecho, los parámetros del modelo ML se sintonizan para la Tarea 1, y luego se ajustan para reflejar los conocimientos relacionados con la Tarea 2. Sin embargo, los nuevos parámetros podrían sobrescribir los conocimientos relacionados con la Tarea 1. Esto está relacionado con el equilibrio entre plasticidad y estabilidad: los parámetros del modelo deben poder adaptarse a los nuevos conocimientos adquiridos (plasticidad) y, al mismo tiempo, conservar los conocimientos antiguos (estabilidad de la memoria).
El olvido catastrófico se ha estudiado ampliamente en el aprendizaje continuo, en el que un modelo de ML aprende continuamente de un entorno en constante evolución, y los métodos de mitigación comprenden la reproducción de datos antiguos, la regularización o las técnicas neuroinspiradas. Sin embargo, sus efectos en el aprendizaje distribuido están menos explorados.
¿Qué es el aprendizaje federado dividido?
En el aprendizaje distribuido, los dispositivos forman de forma colaborativa un modelo ML sin compartir sus datos locales. Por ejemplo, nuestros smartphones forman un modelo ML para poder clasificar fotos, pero sin compartir nuestras propias fotos con los demás. Ahora, podemos pensar en el modelo ML como en una cadena de montaje de una fábrica. Los dispositivos pueden realizar los primeros pasos del procesamiento a nivel local y, a continuación, envían los resultados parcialmente procesados a una «estación de acabado» central (un servidor central). Se trata del Aprendizaje Federado Dividido (SFL). En detalle, SFL es un método de aprendizaje distribuido en el que parte de la formación de los dispositivos se descarga en un servidor. Esto es especialmente útil en los casos en que los recursos de los dispositivos son insuficientes para realizar la formación en el dispositivo (por ejemplo, un sensor pequeño en escenarios de Internet de las Cosas). En la práctica, el modelo ML (es decir, una red neuronal profunda) se divide en dos partes de capas consecutivas (como se ilustra a la izquierda de la figura siguiente): la parte-1 se forma localmente en cada dispositivo, y la parte-2 por el servidor.
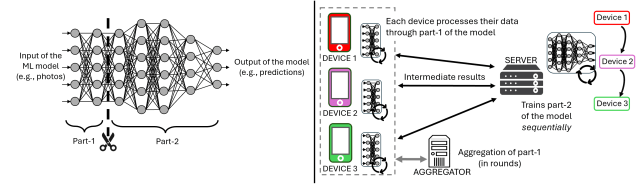
Izquierda: Ejemplo de una red neuronal de 7 capas dividida en Parte-1 y Parte-2 en el marco del aprendizaje federado dividido. Derecha: Los pasos del flujo de trabajo de procesamiento de Split Federated Learning
En la figura de arriba (derecha) se representan los pasos del flujo de trabajo de procesamiento de SFL para 3 dispositivos. Al principio de cada ronda de formación, los dispositivos procesan una parte (lote) de sus datos a través de la parte-1 del modelo, envían los resultados intermedios al servidor, el servidor forma secuencialmente la parte-2 basándose en los resultados recibidos de cada dispositivo y envía los resultados a los dispositivos, y finalmente los dispositivos actualizan sus modelos locales. Estos pasos se repiten para todos los lotes, y una vez que todos los dispositivos han procesado todos sus datos, todas las actualizaciones del modelo se combinan en un modelo global (por el agregador), antes de que comience una nueva ronda.
Claves del olvido catastrófico en el aprendizaje federado dividido
Está claro que, en SFL, la parte 1 del modelo se forma como en el aprendizaje federado (FL). Por otro lado, la parte-2 se forma sobre resultados intermedios que los dispositivos envían en orden secuencial. Este doble aspecto del SFL lo hace especialmente susceptible de sufrir olvidos catastróficos cuando los datos de los dispositivos son muy heterogéneos (por ejemplo, un dispositivo tiene sobre todo fotos de gatos y el otro fotos de perros). En la práctica, nuestros experimentos (en tareas de clasificación de imágenes) revelan que el orden de procesamiento en el servidor tiene un impacto significativo en el olvido catastrófico en el modelo ML.
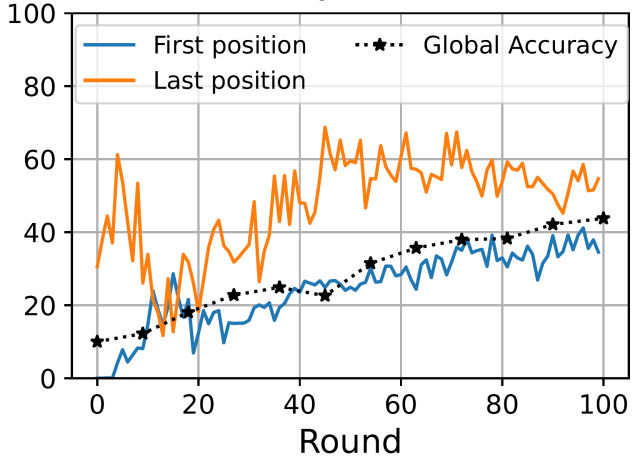
Precisión por posición de procesamiento (en el servidor) y precisión global alcanzada por MobileNet en CIFAR-10 bajo distribuciones heterogéneas de datos entre 10 dispositivos.
La figura anterior muestra el olvido catastrófico en SFL como resultado del orden de procesamiento en el servidor cuando los datos de los dispositivos son heterogéneos. En concreto, suponemos que los datos de cada dispositivo contienen una etiqueta muy representada (por ejemplo, distintos tipos de animales). Nos centramos en el modelo MobileNet (para clasificación de imágenes) que se forma en el conjunto de datos CIFAR-10 (que contiene 10 etiquetas). Las líneas azul y naranja representan la precisión de las etiquetas muy representadas en los dispositivos que se procesan en primera y última posición, respectivamente. Vemos que, bajo datos heterogéneos, la etiqueta que está altamente representada en el dispositivo cuyos resultados intermedios se procesan en último lugar en el servidor supera a la etiqueta del dispositivo que estaba en primera posición. La disparidad de rendimiento entre las etiquetas vistas al final de la secuencia y las vistas antes está relacionada con el olvido catastrófico en la parte-2.
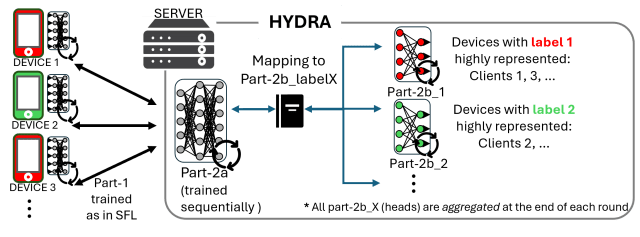
El flujo de trabajo de Hydra, el método propuesto para mitigar el olvido catastrófico en SFL.
H2: Hydra: Un nuevo método para mitigar el olvido catastrófico en el SFL
Basándonos en estos conocimientos, diseñamos Hydra, un método creado específicamente para reducir los olvidos catastróficos en SFL. Hydra mantiene sin cambios la formación del lado del dispositivo, pero modifica el flujo de trabajo del lado del servidor:
- El modelo del lado del servidor se divide en un componente compartido (parte-2a) actualizado secuencialmente y múltiples componentes de cabecera (parte-2b) actualizados en paralelo y fusionados al final de cada ronda.
- Cada cabeza es formada por un grupo de dispositivos con etiquetas similares altamente representadas. Después de cada ronda, todas las cabezas se agregan en un único modelo, lo que reduce el olvido.
- A diferencia de los métodos multicabezal tradicionales en el aprendizaje continuo, Hydra produce un modelo unificado, lo que lo hace eficiente y desplegable.
Nuestras evaluaciones muestran que Hydra mejora eficazmente la precisión, cierra la brecha de rendimiento de las etiquetas y añade una sobrecarga computacional mínima.
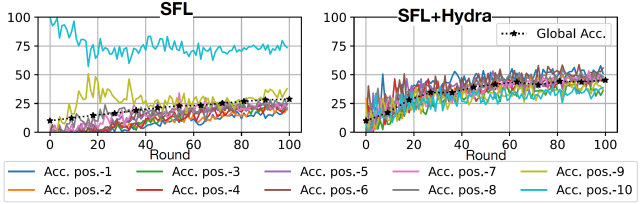
Precisión por posición en SFL y SFL+Hydra lograda por ResNet101 con CIFAR-10 en un entorno de alta heterogeneidad de datos.
La figura anterior ilustra la eficacia de Hydra en la formación de ResNet101 con CIFAR-10 bajo una alta heterogeneidad de datos. Cada línea muestra la precisión de la etiqueta que está altamente representada en los dispositivos procesados en una posición determinada de la secuencia (de la primera a la última). El gráfico de la izquierda corresponde al SFL estándar, mientras que el gráfico de la derecha muestra el SFL mejorado con Hydra. Véase que, a diferencia de la SFL de referencia, Hydra conduce a un rendimiento equilibrado en todas las posiciones de procesamiento. Además, la precisión global mejora significativamente, alcanzando el 44 % en lugar del 28 % tras 100 rondas de formación.
¿Por qué es importante hacer frente al olvido catastrófico?
Muchos modelos de ML y sistemas de IA del mundo real (en sanidad, finanzas y dispositivos móviles) se forman en colaboración a través de múltiples organizaciones o dispositivos. Si los modelos ML olvidan la información aprendida previamente, sus predicciones pueden volverse sesgadas o poco fiables. Al comprender y reducir los olvidos catastróficos, ayudamos a garantizar que los sistemas de ML distribuidos sigan siendo precisos, estables y fiables en su uso en el mundo real.
Próximos pasos
En este trabajo, estudiamos el olvido catastrófico en el aprendizaje federado dividido y propusimos Hydra, una solución eficaz que mejora la precisión global y cierra las brechas de rendimiento de las etiquetas.
De cara al futuro, SFL también plantea retos de optimización relacionados con la sobrecarga de comunicación y la asignación de recursos. Se están estudiando en el marco del proyecto OPALS, financiado por las Acciones Marie Skłodowska-Curie (MSCA).
Si quieres leer el estudio completo, haz clic






